_by_Pablo_Picasso.jpg)
Introduction
In Collected Ficciones (1944), Borges tells the story of the fictional author Pierre Menard. The story is presented in the form of a literary criticism of Menard’s complete works, including “perhaps the most significant writing of our time… the ninth and thirty-eighth chapters of Part I of Don Quixote and a fragment of Chapter XXII.”
The story does not take place in a universe without Cervantes; rather, Menard writes and publishes several identical fragments of Don Quixote (1605). The story goes on to highlight the inherent absurdity of this proposition:
Pierre Menard did not want to compose another Quixote—which surely is easy enough—he wanted to compose the Quixote. Nor, surely, need one be obliged to note that his goal was never a mechanical transcription of the original; he had no intention of copying it. His admirable ambition was to produce a number of pages which coincided—word for word and line for line—with those of Miguel de Cervantes. 1
Menard’s method is simple: method acting. He completely copies Cervantes: he learns Spanish, converts to Catholicism, fights the Moors and Turks, forgets 300 years of history, and so on, until his mind regenerates excerpts of Don Quixote, from scratch.
The comedy escalates when the narrator argues that Menard’s version of the Quixote, though identical in words, is in fact superior to the original version, indeed, “almost infinitely richer”, since Menard had to overcome steeper difficulties to arrive at the same words. For example:
The contrast in styles is equally striking. The archaic style of Menard—who is, in addition, not a native speaker of the language in which he writes—is somewhat affected. Not so the style of his precursor, who employs the Spanish of his time with complete naturalness.
Can two authors write the exact same novel, word-for-word? The notion seems absurd. But why?
In mathematics, ideas are often rediscovered by multiple practitioners. Newton and Leibniz both independently discovered calculus. The proof of the impossibility of a quintic formula was independently proved by both Abel and Ruffini. The Cauchy-Schwarz inequality was discovered independently by Cauchy, Bunyakovsky, and Schwarz, all in different contexts.
And in the arts, it isn’t that unusual to see some degree of convergent evolution. It’s not that hard to find examples:
In cinema: The Prestige (Nolan, 2006) and The Illusionist (Burger, 2006) were released almost simultaneously, both exploring the dark world of Victorian-era stage magicians.
In science fiction: William Gibson’s Neuromancer (1984) and Vernor Vinge’s novella “True Names” (1981) independently2 arrived at similar cyberpunk visions of the future, writing about worlds where humans could mentally connect to global computer networks and inhabit digital avatars. Both featured hackers battling artificial intelligences virtual domains, and both explored how digital technology would transform human consciousness and identity.
In music: there was a creative dialogue between the Beatles and the Beach Boys in the mid-1960s as both bands pushed towards new frontiers of psychedelic complexity. The Beatles’ Rubber Soul (1965) inspired Brian Wilson to create Pet Sounds (1966), which in turn influenced the Beatles’ approach to Revolver (1966). In early 1967, when Brian Wilson first heard “Strawberry Fields Forever,” he pulled over in his car, broke down in tears and said, “They got there first.”
Nonetheless, something still seems wrong with the Menard example. The exact word-for-word replication of an existing work seems too improbable to be coincidence.
Artists are Highly Specific
…if we want to write fiction that flows, we need to explore the syntax of our prose on all levels, from the micro level of the sentence to the macro level of the complete work.
–David Jauss3
The difference between the almost right word and the right word … [is] the difference between the lightning bug and the lightning.
– Mark Twain4
Suppose you’re writing a novel, and you have very specific tastes: down to the level of individual words. Top literary figures are known to do this. Nabokov wrote his drafts on index cards, which allowed him to constantly rearrange sentences and paragraphs until he achieved the exact effect he wanted. He would write and rewrite some cards dozens of times. For Lolita (1955), he reportedly filled over two thousand index cards with revisions. T.S. Eliot would sometimes spend hours deliberating over the placement of a single comma. Ernest Hemingway claimed to have rewritten the ending to A Farewell to Arms (1929) 39 times before he was satisfied. When asked what had stumped him, he said he was “getting the words right.”
At the utmost extreme is perhaps James Joyce, commonly considered to be one of the greatest writers of all time5:
Notoriously slow, or rather careful, at crafting his prose, a famous story, perhaps apocryphal, involves a friend who visited Joyce to find him dejectedly slumped over a page. When asked how much he had written that day, Joyce answered, “Seven words.” Laughing, his friend said that was an achievement for him. Joyce replied, “But now I have to find the right order for them!”6
This underlines the absurdity of the Menard story. If Cervantes labored as deeply as Joyce, then in order “to write the Quixote”, Menard’s transformation must be so complete as to capture Cervante’s specific sensibility about the precise ordering of individual words.
The full Don Quixote is roughly 430000 words long. If Menard writes the Quixote one word at a time, that’s 430000 decisions7 that Menard and Cervantes must agree on exactly.
Word Machines
Large language models also generate words (or any tokens) one-at-a-time.
[Large language models] are highly general purpose technology for statistical modeling of token streams.
– Anrej Karpathy
There are a lot of people attempting to engineer computer systems to produce art. And clearly AI systems can be used to make “art”, by some definition. They certainly can produce text and images.
But can AI be used to make your art?
Consider an artist8 trying to produce a text using an AI tool. Taste can be microscopic: some authors deeply consider each word for criteria such as rhythm, diction, placement, etc. If an artist has taste relative to each word in the final piece of text, then in order to instruct the AI to produce the desired work, the specification must contain as much detail as necessary to specify the final work. The author must guide the AI to output the text at the word-level granularity.
Most popular artificial intelligence systems are guided using prompts, written in English. The final novel is also written in English. The author could just specify the novel by writing the novel, instead of prompts. And the elite authors we saw before have extremely specific tastes, down to the specific word. But we can tell that prompts make our writing process faster. How can this be? How can we specify some number of words using some lesser number of words?
You may be reminded of another one-paragraph Borges story, “On Exactitude in Science” in which cartographers create a map so detailed that it matches the empire’s territory at a 1:1 scale, rendering it ultimately useless. We find ourselves in a similar paradox. We need to use a small number of words to specify a larger number!
So even in the presence of a “perfect oracle”, we need to communicate what we want. How much information will we need to specify to get back exactly our desired result?
Platonic Theories of Art
I saw the angel in the marble and carved until I set him free.
– Michelangelo9

In yet another story, The Library of Babel, Borges describes an infinite library:
The universe (which others call the Library) is composed of an indefinite, perhaps infinite number of hexagonal galleries… and that its bookshelves contain all possible combinations of the twenty-two orthographic symbols (a number which, though unimaginably vast, is not infinite) - that is, all that is able to be expressed, in every language. All - the detailed history of the future, the autobiographies of the archangels, the faithful catalog of the Library, thousands and thousands of false catalogs, the proof of the falsity of those false catalogs, a proof of the falsity of the true catalog, the gnostic gospel of Basilides, the commentary upon that gospel, the commentary on the commentary on that gospel, the true story of your death, the translation of every book into every language, the interpolations of every book into all books, the treatise Bede could have written (but did not) on the mythology of the Saxon people, the lost books of Tacitus.
The libary contains all of the combinations of some limited set of orthographic symbols, comprising all possible texts. That is, the texts exist already, out in the Platonic realm. Rather than creating texts, humans (and any other intelligent agents) merely sample from the manifold of texts in the library and determine which texts they find most interesting.
The notion of reducing the art form to search isn’t confined to literature. It’s not even academic. In some art forms we actually can and have already algorithmically pregenerated all possible works.
In March 2020, musician and lawyer Damien Riehl and programmer Noah Rubin used an algorithm to create every possible melody. The goal was to show that the number of possible melodies is finite, and that artists might unintentionally repeat patterns. Similarly, Alexander Reben’s All Prior Art project used algorithms to generate and publish millions of potential inventions, aiming to prevent patent trolling by creating technically “prior art” for yet-uninvented devices. In the visual realm, John F Simon Jr.’s Every Icon project systematically generates all possible 32x32 black and white pixel combinations, methodically working through the finite (though vast) space of possible simple images. And there are real attempts to produce the library of Babel on the internet.
If all possible texts have already been created, what does it mean to produce a text? In this framing, the texts are “discovered”, not “created” (or perhaps more aptly, discovery is no different from creation).
The problem becomes: how do you find the text you want in the library?
We also have knowledge of another superstition from that period: belief in what was termed the Book-Man. On some shelf in some hexagon, it was argued, there must exist a book that is the cipher and perfect compendium of all other books, and some librarian must have examined that book; this librarian is analogous to a god… For a hundred years, men beat every possible path and every path in vain. How was one to locate the idolized secret hexagon that sheltered Him? Someone proposed searching by regression: To locate book A, first consult book B, which tells where book A can be found; to locate book B, first consult book C, and so on, to infinity….
Within the library, there is an index of the library. The (reader of) the index is “the Book-Man”, a theoretical, omniscient library index that contains (or can retrieve) every possible text. So if you have a copy of the index, you can find any information you desire. But we still have to expend the energy to look up entries in the index (and retrieve the actual book).
We can think of the Book-Man as being similar to having an Artificial Super Intelligence. Any real AI system is limited by scope and training data. It will only be a partial or approximate index of the library. Perhaps it will even have some errors10. Either way, for the sake of this essay, let’s assume our Book-Man has perfect recall of the index and can be queried in any language, including English.
So: if the AI is Book-Man, and it can find us any text, how will we tell it which exact text we want?
Information Theory
Most likely we will want to query the Book-Man in English (though perhaps we might devise some ciphers, decision trees or other methods of interacting with the Book-Man).
Let’s first consider the simplest possible text: a text of a single word.
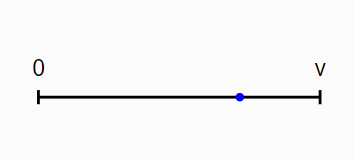
This picture is a line. Each point on the line represents some word from the vocabulary. Suppose the vocabulary has \(v\) words. We have one dimension, a \(v\) possibilities. The blue point represents the selection of a single word, and thus defines a text.
Now let’s consider a text of two words:
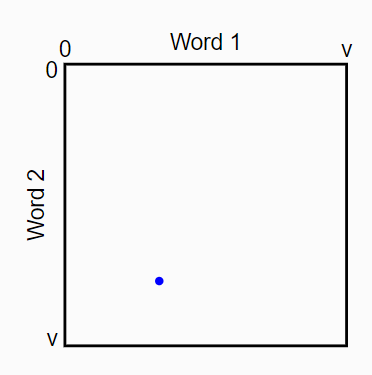
This picture is a square. Each point in the square represents some pair of words, both drawn from the vocabulary. Suppose the vocabulary has \(v\) words. We have two dimensions, or \(v^2\) possibilities. The blue point represents the selection of a particular two word sequence.
We can generalize this. If \(k\) is the text length and \(v\) is the vocab size, we have:
\[ N_{texts} \leq v^{k} = 2^{\frac{k\log(v)}{\log(2)}} \]
The above examples are very simplified. How many bits does it take to specify an actual text we might be interested in? Menard only “wrote” part of the Quixote, but let’s take a look at the complete Don Quixote, alongside some other works. The following table gives some illustrative word counts.
| Words | Work | Author | Year | Note |
|---|---|---|---|---|
| ~10 | Typical Haiku | - | - | Japanese poems |
| ~100 | Ozymandias | Shelley | 1818 | Classic sonnet |
| ~1,000 | The Tell-Tale Heart | Poe | 1843 | Short story |
| ~10,000 | The Metamorphosis | Kafka | 1915 | Novella |
| ~50,000 | The Great Gatsby | Fitzgerald | 1925 | Minimal novel |
| ~80,000 | Typical novel | Industry standard | ||
| ~100,000 | 1984 | Orwell | 1949 | Substantial novel |
| ~200,000 | Moby Dick | Melville | 1851 | Long classic |
| ~430,000 | Don Quixote | Cervantes | 1605 | Major novel |
| ~1M | In Search of Lost Time | Proust | 1927 | Longest “canonical” novel |
| ~3.3M | King James Bible | - | 1611 | - |
| ~4.5M | Artamène ou le Grand Cyrus | Scudéry | 1653 | Longest published novel |
| ~5.6M | At the Edge of Lasg’len | Taure | 2025 | LOTR Fan Fiction |
| ~9M | Mahābhārata | - | ~400BC | Longest poem |
| ~4.7B | Wikipedia | - | 2025 | Modern corpus |
The full Don Quixote is roughly \(430000\) words11 long. This is relatively long for a novel. Let’s be conservative and instead say the user is looking for a text the size of an industry standard novel (\(80000\) words). The entire English vocabulary is estimated at around \(170000\) words (in common usage) up to maybe \(1000000\) words (including all archaic words).
For the average length novel, allowing archaic words, this is \(1000000^{80000}\), or roughly \(2^{1860280}\).
So if the Book-Man were to give you a series of yes/no decisions about your text, you would have to make \(1860280\) independent binary decisions to specify all \(80000\) words. So roughly \(1860280\) bits are required to index a specific average length novel.
However, this is an overestimate. Many of the possible texts in the library would be gibberish. The actual information content of a novel is constrained by several factors:
Grammar. Let’s say on average, at each position, roughly 75-80% of words are impossible.
Word frequencies tend to follow Zipf’s law. The most common 100 words comprise about 50% of all texts.
Local context heavily constrains word choice.
Global narrative coherence further restricts possibilities.
Classic estimates by Claude Shannon found English text to have around 1–2 bits of information per character, which translates to ~10–12 bits/word (assuming ~5–6 characters/word). This can be supported both by the theoretical arguments and compression experiments. So we need 100KB+ to specify an 80000 word novel.
Implications
What are the implications of this?
Prompt Size
Prompts need to be more information-dense than typical prose - they are compressed specifications of desired content.
Even so, prompts are still constrained by:
- English grammar and word frequencies
- Common instructional language patterns
- Limited semantic scope (they describe rather than embody content)
- Human-readability
Given these constraints, a reasonable upper bound might be 14-15 bits per word of unique specification information. For a 50-word prompt, this suggests around 700-750 bits of actual content specification. A 200-word prompts would give 2800 to 3000 bits of information.
If prompts were significantly more information-dense than 15 bits per word, they would become effectively steganographic. It is very difficult for humans to write this way. This puts a fundamental limit on how much unique information a prompt can carry.
Text Specification
How many prompts do we need to find a specific text?
Well, if we are going from 10-12 bits/word in the final work, to 14-15 bits/word in the prompt, this is at best a 0.66 reduction in writing.
So, to fully specify a novel-length work, we would need:
- For Don Quixote (430000 words):
- 283000 words in prompts
- At 50-200 words/prompt: ~1400-6000 prompts
- For a typical novel (80000 words):
- 52800 words in prompts
- At 50-200 words/prompt: ~264-1056 prompts
This is a excellent efficiency improvement (+50%). However, it’s a far cry from one-shotting the novel. Furthermore, if contradictory bits are given in the prompts, or if there’s information loss in the process, the actual prompt requirements will exceed these analyses.
Speedup
What kind of latency speedup do we get?
Traditional novel writing time (80000 words):
- Fast professional pace: 2-3 months (4000 words/day)
- Typical professional pace: 6-12 months (2000 words/day)
- Slower/more deliberate pace: 12-24 months (500-1000 words/day)
With AI assistance, at a 1.5x gain:
- Fast pace: 1-2 months
- Typical pace: 4-8 months
- Slow pace: 8-16 months
We need additional information to specify the novel, either from iterative refinement, external knowledge sources, or human guidance. There’s simply no way to compress the necessary specification into a single prompt or even a small set of prompts12.
Preference Oracles
To fully specify a novel-length work requires hundreds of kilobytes of information, far more than can be contained in a typical prompt. So even with access to the Book-Man, there is still a role for humans to play: that of the preference oracle.
Rather than specifying every detail of their design upfront, humans can iteratively select between alternatives presented by the AI system. Each selection provides additional bits of information about the desired output. This is more efficient because:
- Selection is cognitively easier than generation. A human may struggle to articulate exactly what they want, but can often recognize it when they see it.
- Each binary choice provides one bit of information. A human selecting between \(8\) alternatives provides \(3\) bits.
- The AI can use each selection to better model the human’s preferences, making future alternatives more likely to be useful.
But suppose we really want to one-shot a novel-length text. How might we go about it?
Resolutions
Random Sampling
Let’s return to our information theory analysis. A novel contains about 100KB+ of information. Through prompts, we can only specify a small fraction of these bits. What if we simply generated the remaining bits at random and let the author select which random completion they prefer?
The simplest approach would be pure random sampling: generate many possible completions, each with random values for all unspecified bits, and let the author choose their favorite. This is appealing because it requires no additional machinery: we just need a random number generator and a way to show the results to the author.
However, if we have 100KB (800000 bits) of unspecified information, we’re choosing from \(2^{800000}\) possibilities. Even if we generated a billion samples per second, we’d need far longer than the age of the universe to find one that matches all our preferences. And this assumes we only need to find one acceptable sample. If we want to give the author meaningful choice between alternatives, we’d need to find multiple good samples.
We could try to make this search more efficient using structured approaches like grid search, importance sampling, genetic algorithms, or gradient-based methods. These techniques could focus our sampling on more promising regions of the space, dramatically reducing the number of samples needed to find acceptable completions.
But perhaps the real insight is that not every bit matters equally to the author. Maybe we don’t need to find completions that match ALL our unspecified preferences. Maybe they just need to match the ones we care about most.
Abstraction

Artists don’t have to actually decide on every word. One solution is not making word-specific decisions, but decisions at a higher level of abstraction. Genre conventions, for example, might dictate lots of information about a novel.
Let’s consider a (highly simplified) hierarchical model of a novel. At the topmost level is the premise of the novel. Based on the premise, we produce various plot events. For each plot event, we produce a number of paragraphs. For each paragraph, we must produce a number of words.
This hierarchy suggests a more efficient approach to specification. Instead of trying to control every word choice, we could specify high-level decisions and let lower levels be determined algorithmically. This is far less than specifying all the words directly. The abstraction approach says: specify the important high-level decisions, then let lower-level details emerge naturally from those constraints.
So maybe the author doesn’t want to point to a specific “point” in the space of texts. Maybe a region will do. For example, in the visual arts, an artist might not care about the actual details in a particular region of the painting, just the average color.

But this raises a crucial question: how do we ensure the lower-level details properly reflect the artist’s taste? When the AI system expands “Bob confronts his fear of heights” into specific paragraphs and sentences, how do we guarantee those expansions match what the artist would write? Either that’s not part of the artists vision (it’s abstracted) and it doesn’t matter, or we need to specify it. Either way, we aren’t saving any effort.
So the abstraction approach hasn’t actually improved anything. It’s just pushed the work around. We still need some way to ensure all the necessary choices align with the artist’s sensibility.
Personalization
Predicting the next token well means that you understand the underlying reality that led to the creation of that token… What is it about people that creates their behaviors? Well they have thoughts and their feelings, and they have ideas, and they do things in certain ways. All of those could be deduced from next-token prediction.
–Ilya Sutskever13
Maybe the AI will know our tastes, our thoughts, our feelings, and will use those to guide it in selecting the ideal string we want. Like Menard acts as Cervantes, the AI will replicate our tastes and use them to guide the search.
The personalization approach treats human attributes as compressed representations of artistic choice patterns. Statistical correlations between demographics and writing style could theoretically let us predict an author’s preferences without explicitly stating them.
The recipe seems clear. Given “prompts” and our personalized “taste information” we can produce our desired “work of art”.
So perhaps we can specify the remaining bits using demographic and personal information about the author. After all, much of what shapes artistic decisions comes from one’s background:
- Age and generation
- Cultural background
- Educational history
- Geographic location
- Professional experience
- Reading habits
- Social circles
- Political views
- Life experiences
Rather than trying to specify every choice explicitly, we could provide this demographic information to the AI system and let it infer the likely artistic decisions. This is appealing because demographic data is readily available and relatively compact to specify.
How many bits might we get? Let’s estimate how many bits of information these factors might provide:
- Age (0-100 years): ~7 bits
- Location (among ~200 countries): ~8 bits
- Education level (8 levels): ~3 bits
- Field of study (among ~100 fields): ~7 bits
- Profession (among ~1000 categories): ~10 bits
- Political alignment (on 5 major axes): ~10 bits
- Religious beliefs (among ~4000 denominations): ~12 bits
- Language(s) (among ~6500 languages): ~13 bits
- Cultural background (~500 ethnic groups): ~9 bits
- Major life events (100 possible significant events): ~7 bits per event
Even being generous with our estimates, we might capture ~1KB of information through detailed demographic profiling. That’s far short of the 100KB+ gap we need to fill.
Extreme Personalization
We could try collecting truly exhaustive personal data:
- Biological data: DNA, scans, hormones, vitals, records
- Media consumption: Books, films, shows, music, podcasts consumed
- Communication: Conversations, emails, texts, comments, calls logged
- Digital footprint: History, queries, clicks, movements, interactions
- Written output: Documents, notes, drafts, journals, lists created
- Physical data: Location, sleep, fitness, diet, daily movements
- Social connections: Complete history with all human interactions
- Environmental exposure: Climate, sound, air, light conditions faced
- Education: Academic data, assignments, notes, participation record
- Professional: Career history, projects, meetings, reviews, outcomes
- Financial: Transactions, investments, budgets, purchases tracked
- Cultural: Languages, travels, events, traditions experienced
- Emotional: Moods, reactions, stresses, joys, fears documented
A comprehensive dataset like this would be massive. Even after we account for massive redundancy in daily patterns and apply compression, we’re still left with gigabytes of information about a person - far more than the 100KB+ needed to specify a novel.
Now we have a new problem: which life experiences does the person want to use to determine the novel?
If artistic choices are purely a product of life experience, we should be able to predict them from this data. In some ways, TikTok and similar recommendation algorithms can be thought of as “taste machines” in this way. They optimize for specific metrics (engagement) rather than artistic authenticity.
So given enough data and computing power, we might be able to learn this mapping. We might be able to build a model that, given sufficient information about someone, can predict their extremely low-level choices14.
The deeper question is: what would such a model mean? If we succeed in building it, what have we actually captured?
Art and Identity
By their fruits ye shall know them.
–Matthew 7:20

The extreme personalization approach suggests that if we provide enough information about an artist, we can predict their artistic choices.
But consider what we’re saying we need to predict artistic decisions:
- Past experiences and memories
- Knowledge and understanding
- Cultural context
- Personal history
- Technical training
- Emotional patterns
- Genetics
If we really have all of this information in the computer, and it’s used to predict what word comes next, who is really choosing the word? What aspects of the person aren’t being used to produce the desired output? What part of their identity could be removed without affecting our artistic choices?
This brings us to the core paradox. To fully model someone’s artistic selections, we need enough information to predict all their creative decisions. But this requires putting everything about them into the machine. We need both a complete compressed representation of the person somewhere, as well as a function that predicts their actions based on that representation. Could be in the inputs, the taste function, or the Book-Man.
But if we have a complete compressed representation of the person, and a function that predicts their next low-level decision… isn’t that still them making the decisions? We haven’t automated the person away. We’ve just moved them to a different medium.
Conclusion
Artists are specific, often down to the word. Compression ratios and text specification shows that to specify a novel-length work requires hundreds of kilobytes of unique information: far more than can be captured in prompts or high-level descriptions. The various proposed solutions all fail to resolve the fundamental paradox: to perfectly recreate someone’s artistic choices, you must recreate their thought process.
This explains why the Menard story is absurd. To truly write the Quixote would require becoming Cervantes — not just knowing what Cervantes knew, but deciding in the way Cervantes was deciding. The words of the Quixote aren’t just a string of characters; they’re the fingerprints of his specific choices.
If someone had the Book-Man, and they wanted to read about Cervantes, they would put the name “Cervantes” into the Book-Man. If someone had the Book-Man, and they wanted to read about you or your works, they would put your name into the Book-Man.
Menard became Cervantes to write the Quixote. Menard can’t have written the Quixote, because to write the Quixote, you must be Cervantes. And Cervantes by any other name is still Cervantes.
And as Borges writes:
In all the Library, there are no two identical books.
Read More
After writing this essay, I became aware of a nice article by Leon Bottou and Bernhard Scholkopf called “Borges and AI” (a reference to the Borges story “Borges and I”) that references several Borges stories, including “The Garden of the Forking Paths” and “The Library of Babel”.
Ditto several similar posts pointing in the same direction (convergent evolution). Please let me know if you know of others I missed.
Changelog
01-24-2025 - Added “Read More” section
Footnotes
trans. Andrew Hurley, Collected Fictions (1998)↩︎
It’s possible Gibson was aware of “True Names”. I’ve see claims that he wasn’t, but I can’t find evidence either way.↩︎
“What We Talk About When We Talk About Flow” (2011)↩︎
Letter to George Bainton (1888)↩︎
Nabokov, famously a harsh critic who referred to Camus as “awful”, Hemingway as “hopelessly juvenile” and Faulkner as a “writer of corn-cobby chronicles”, said that Joyce was a “genius” and that Ulysses (1922) was the “greatest masterpiece of 20th century prose.”↩︎
Apocryphal quote↩︎
Ignore that Menard wrote just part of the Quixote, for the sake of discussion.↩︎
Note that we are focused on art here. Analyses of math, science, engineering, etc. are different, as the texts may be constrained by external forces (such as reality) and the size of the text may be much larger or indeterminate (like reading from the Book of Sand). I’m also ignoring any “natural” aesthetics (like mountains). Calling it “art” let’s us do away with all that. Perhaps someday I will attempt to extend this analysis beyond art.↩︎
Apocryphal quote↩︎
This is another interesting question. If we have an “approximately correct” index of the library, can we use it to find the “true” index of the libary? How much effort would we have to expend? Through, say, repeated querying, iterative refinement, or “meta-prompts”? Maybe more on this in a future post.↩︎
I’m using words, rather than tokens or characters. Analysis with tokens should be similar.↩︎
Another way that AI might speed up text creation is via new input modalities, i.e. dictation. This is omitted from the analysis.↩︎
https://www.dwarkeshpatel.com/p/ilya-sutskever↩︎
If we have a static taste function, then single short texts could actually be “overdetermined”. This could explain convergent evolution to some degree. However, the “taste” function might have to be expanded to include all choices that the person makes over their entire lifetime, so I think it’s still underdetermined. Regardless, in practice, we need a lot of personalization information to determine even a single novel length text.↩︎